


Summarize this blog post with:
In this article, you’ll learn the ten data-backed factors that determine whether Perplexity cites your brand, what tactics looked promising but had zero measurable impact, and how to build a repeatable system for earning (and keeping) Top-3 citations.
Every finding here comes from analyzing 83,670 citations across ChatGPT, Claude, and Perplexity over 54 days. We tracked ranking position, source domain, content type, query match, freshness, and structured data for each result. Then we ran statistical tests to isolate which factors actually correlated with Top-3 placement.
The short version: Perplexity does not behave like Google. It does not behave like ChatGPT either. It has its own retrieval logic, its own biases, and its own blind spots. If you optimize for it the same way you optimize for traditional search, you will miss what actually moves the needle.
Here is what does.
Table of Contents
How Perplexity Selects Sources (and Why It Matters)
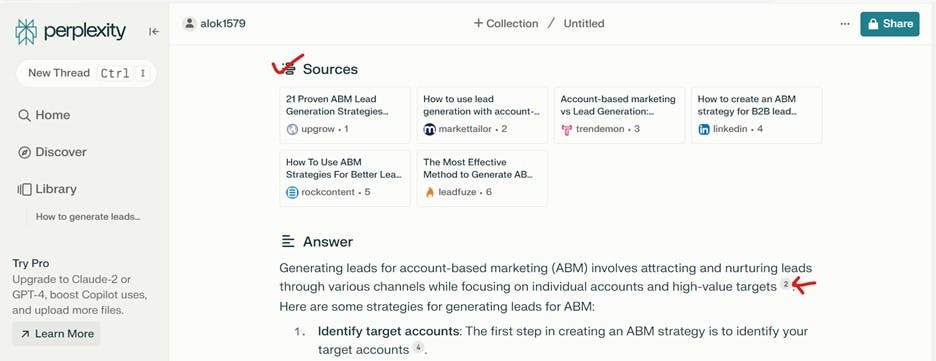
Perplexity is a citation-first answer engine. Unlike ChatGPT, which leans on parametric knowledge and only sometimes cites sources, Perplexity runs a live web search for every query. It retrieves candidate pages, reranks them through a multi-layer pipeline, then cites the top 3 to 8 sources inline.
That architecture creates a key difference. In traditional SEO, your page competes for a position in a list of links. In Perplexity, your page competes to be extracted from. The model is not sending users to your page. It is pulling facts out of your page and citing you as the source.
This means the content that wins on Perplexity is not always the content that wins on Google. Perplexity rewards extractability (how cleanly can the AI lift a fact from your page), freshness (how recently was this updated), and topical consistency (does this domain keep showing up in related prompts).
Our 83,670-citation study also revealed that each AI engine behaves very differently. Perplexity never cited Wikipedia in our dataset. ChatGPT used it for 12.1% of citations. Claude cited it twice. Perplexity provides 1.26 citations per brand mention, 29% more than ChatGPT. And while ChatGPT favors product pages (60.1% of citations), Claude favors blog content (43.8%).
The takeaway is simple. You cannot optimize for “AI search” as a monolith. Each engine has its own retrieval behavior, and Perplexity’s is distinct enough to warrant its own strategy.
The 10 Factors That Drive Perplexity Citations
We ranked these by correlation strength. Each factor is tied to statistically significant differences between Top-3 and non-Top-3 citations.
1. Visibility score across related prompts
Top-3 brands had 42 to 55% higher visibility scores than non-Top-3 brands. The Spearman correlation with position was -0.49 (p < 0.001).
This was the single strongest predictor we found. Brands like Nike, Salesforce, and Booking.com don’t just rank for one prompt. They appear across clusters of related prompts. When Perplexity’s retrieval system sees your domain showing up in “best CRM software,” “CRM for small business,” and “Salesforce alternatives,” it starts treating you as a default source for that entire topic cluster.
This creates a flywheel. More visibility in a cluster means more citations. More citations mean higher trust. Higher trust means you show up in new prompts in that cluster without any additional work.
What to do: Stop targeting individual prompts in isolation. Map your priority topics, then build content that covers the full cluster. You need assets for the head term, the comparison terms, the “alternatives to” terms, and the niche variations.
2. Citation count within a topic
Citations correlated at -0.44 with position (p < 0.001). Top-3 brands averaged 1.7x more citations than others.
If visibility score measures breadth, citation count measures depth. Perplexity is less willing than ChatGPT to rotate in a fresh source if an incumbent already has a strong citation history. Once you’ve been cited 8 or 9 times in a topic cluster, you become the default.
What to do: Focus on winning multiple prompts within a cluster, not one perfect page. Each citation compounds.
3. High average rank across queries
Correlation with Top-3 position was -0.39 (p < 0.001). Domains that perform well in one area get a lift in adjacent areas.
HubSpot ranks for “best digital marketing certifications” partly because it performs well across dozens of related marketing prompts. Perplexity appears to apply this “reputation uplift” more aggressively than ChatGPT.
What to do: Build a portfolio of high-performing content in your strongest areas first. Then branch into adjacent topics where your existing reputation can give you a head start over competitors who are starting from zero.
4. Content freshness
Correlation with Top-3 position was -0.36 (p < 0.01). Perplexity has a stronger recency bias than ChatGPT.
In fast-moving sectors, newer pages routinely displaced older, higher-authority incumbents. For “Top AI coding tools in 2026,” smaller AI-focused blogs outranked legacy tech publishers simply because their articles were updated within the last few weeks.
What to do: Build a content refresh cadence tied to the pace of change in your category. In volatile markets, monthly updates may be necessary. In slower categories, quarterly is enough.
5. Q&A and direct answer formats
Q&A or direct answer formats had a 55% Top-3 rate versus a 31% average (p < 0.01).
Perplexity is more literal in its extraction than ChatGPT. Where ChatGPT will synthesize an answer from multiple pages, Perplexity is more likely to lift a discrete block of text from one page if it directly mirrors the query.
What to do: Identify your highest-value prompts. Make sure at least one page opens with a 1 to 2 sentence direct answer, then supports it with depth below. Structure content around the exact questions your audience asks.
6. Domain authority
Domain trust metrics correlated at -0.31 to -0.34 with position (p < 0.05). Authority functions as a tie-breaker when multiple pages match a query.
This factor matters less than visibility score or citation count on its own. But it plays a supporting role in competitive queries where freshness and exact-match signals are close.
What to do: If you don’t have strong domain authority, lean harder into freshness (factor 4) and exact keyword match (factor 7). Those give you the best chance of leapfrogging entrenched brands.
7. Exact keyword and phrase match
Match score correlated at -0.33 with position (p < 0.01). Top-3 brands averaged 9 points higher in match score.
This is where Perplexity diverges most from ChatGPT. ChatGPT tolerates partial or semantic matches. Perplexity prefers pages whose titles, headings, or metadata mirror the exact wording of the query.
What to do: Create assets that target the exact prompt wording you want to rank for. Match title tags, H1s, and key headings to high-value query phrasing. This is an easy, high-impact win. The Analyze AI Content Optimizer scores your page against the prompts you want to win, then shows you exactly which phrasing gaps to close.
8. Topical breadth
Correlation with Top-3 position was -0.28 (p < 0.05).
In “best home espresso machines,” the highest performers were not standalone product reviews. They were part of a broader content footprint that also included maintenance guides, bean selection articles, and grinder reviews.
What to do: Map every adjacent question your audience asks around a priority topic. Build content for each one. The goal is not just one great page. It is an ecosystem that reinforces your authority in Perplexity’s retrieval model. This is topic clustering at work.
9. Listicle format
Listicles had a 50% Top-3 rate (p < 0.05). They work because they make fact extraction easy for a retrieval system designed to pull discrete, verifiable data points.
What to do: If your target query implies a ranked or comparative answer (“best,” “top,” “most”), format your content as a clean, scannable list with entity names in headings.
10. Structured data and schema markup
Schema-enabled pages had a 47% Top-3 rate versus 28% without (p < 0.05).
Pages with FAQPage, Product, or ItemList schema outperformed similar pages without markup, even when the visible content was nearly identical. Perplexity uses schema as a confidence boost that makes it easier to identify and cite your content.
What to do: Implement the right schema types for your content format. FAQPage for Q&A content, Product for reviews, ItemList for listicles, HowTo for tutorials. This is not just about Google rich snippets anymore. It is about making your pages more retrieval-friendly for AI systems.
What Didn’t Work
Not every tactic that works in Google translates to Perplexity. These showed no measurable lift in Top-3 placement in our dataset:
|
Content Type |
Why It Failed |
|---|---|
|
Generic news articles |
Fresh but broad. Recency only helps when paired with exact-match phrasing and topic alignment. |
|
Thin product blogs |
Short update posts without depth, breadth, or structural cues were invisible in competitive prompts. |
|
Corporate PR pages |
Almost never ranked unless the query was directly about the brand itself. |
|
Standalone product pages |
Rarely ranked without existing visibility and citation momentum. List or Q&A pages from the same domain outranked them. |
|
Social media posts |
Negligible presence in Top-3 results for informational or comparative prompts. |
The pattern is clear. Perplexity rewards structured, comprehensive, extractable content. It deprioritizes content that is shallow, self-promotional, or not directly aligned with how users phrase their queries.
How to Track and Improve Your Perplexity Visibility

Knowing the factors is one thing. Measuring where you stand on each one, and tracking whether your changes are working, is another.
Here is the exact playbook we use.
Step 1. Search the prompt live and see where you stand
Type the exact natural-language prompt into the Analyze AI Search Explorer and run it. You will get live results from ChatGPT, Claude, Gemini, and Perplexity side by side, with Top-3 position, visibility percentage, citation URLs, and brand mentions for each engine.
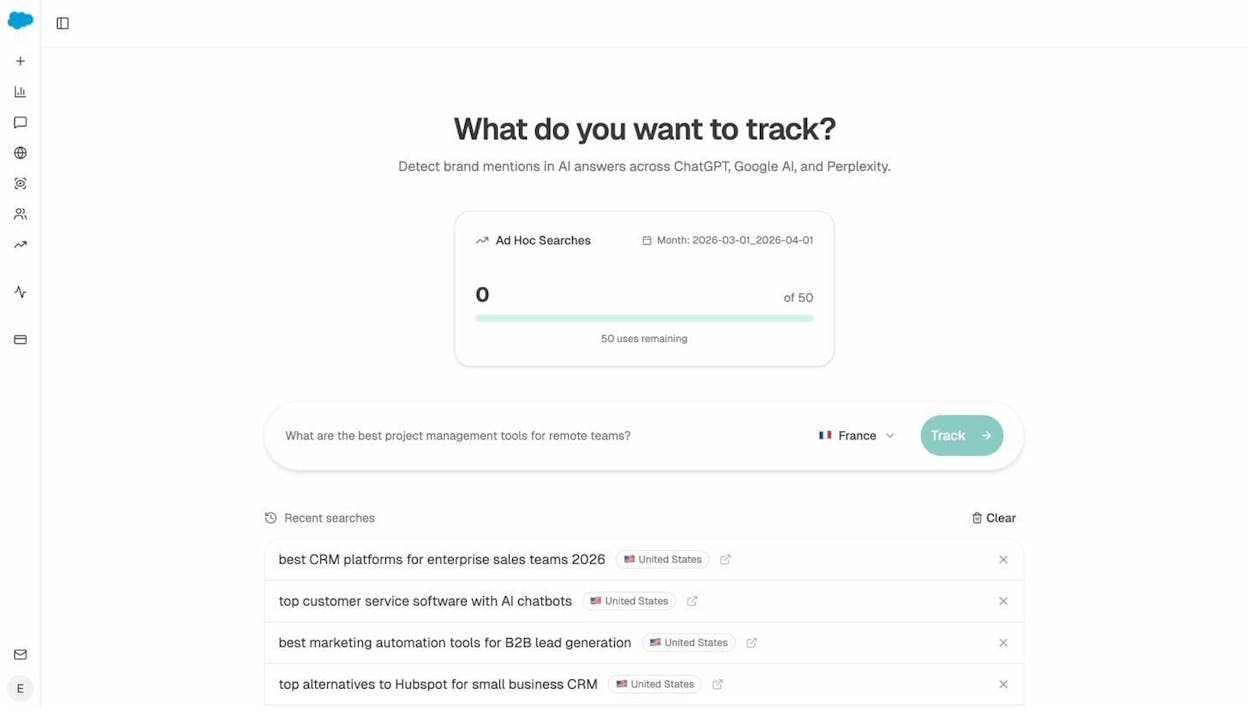
Look at who is in the Top 3 for Perplexity specifically. Look at what URLs Perplexity is citing. Look at whether your brand is mentioned at all.
Step 2. Diagnose why you are (or are not) getting cited
Click into the Sources view. You will see the exact URLs each engine is grounding on, what content types they prefer, and which domains dominate your topic.
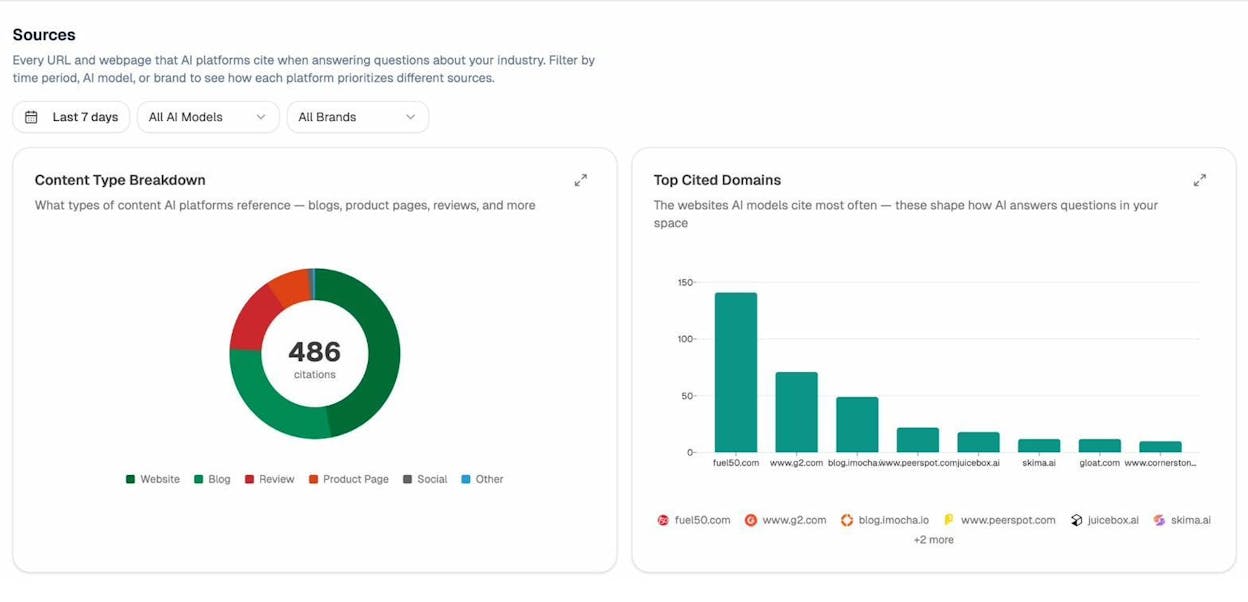
Ask yourself: Do winning pages use the prompt’s phrasing in their titles? Are they listicles or how-tos? Are they recently updated? Do they have schema? Are they from domains that Perplexity reuses across related prompts?
Document the gap between what ranks and your closest page. This turns “we’re not there” into a specific list of things to fix.
Step 3. Track the prompts that matter to your business
You can track each prompt inside Analyze AI’s Prompt Tracking, and the platform will re-query it daily across all models. You get position, visibility, Top-3 changes, and citation deltas over time.
Add 3 to 5 near-neighbor prompts to create a mini-cluster. Ranking gains rarely happen from a single page. They compound across related prompts.
Step 4. Fix your content to match the factors that matter
Use your diagnosis to brief specific changes. Rewrite the title and H1 to mirror the prompt. Restructure the page into a numbered list or step-by-step guide with clear subheads. Add a crisp direct answer up top. Publish current-year data. Add schema matching the format. Strengthen internal links across your prompt cluster.
Step 5. Measure whether it worked
Open AI Traffic Analytics to see whether AI-referred sessions are growing. You can filter by referring engine (chatgpt.com, perplexity.ai, claude.ai) and see which landing pages are receiving traffic.
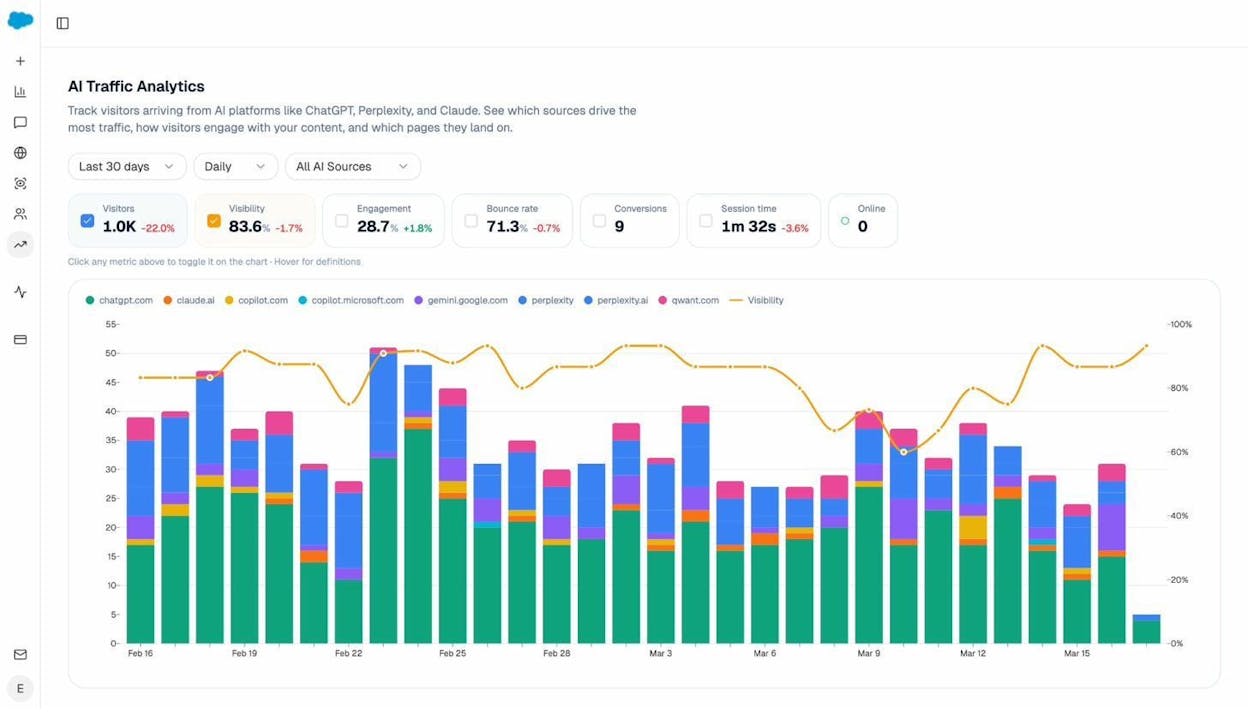
Tie uplift back to the specific changes you made. This is how you build a repeatable process instead of one-off guesswork.
Step 6. Automate the monitoring
This is where most teams stall. They do the work once, see some results, then forget to check again for months.
The Analyze AI Agent Builder eliminates that problem. With 180+ nodes, 34 pre-built data recipes, and direct integrations with GA4, GSC, DataForSEO, Semrush, HubSpot, Notion, WordPress, Slack, and every major LLM, you can build agents that run your entire Perplexity visibility program on autopilot.
A few examples of what teams actually build:
Daily visibility regression alert. Schedule an agent for every morning. It pulls your visibility-losers data, checks if any prompts dropped overnight, and sends a Slack alert with the affected pages and a draft content brief.
Weekly Perplexity audit. The agent pulls your tracked prompts, cross-references them with competitor citation data, identifies which competitors gained ground, and pushes a prioritized action list to Notion.
Content refresh fleet. A scheduled agent checks for stale pages losing citations, scrapes them, rewrites for freshness and AEO readiness, scores the rewrite against your brand voice, and publishes directly to WordPress if the quality gate passes.
These are not templates. They are composable workflows built from primitives. You can wire a GA4 traffic node into a Semrush keyword research node into an LLM prompt node into a HubSpot CRM update. The substrate understands your AI visibility data, your search console data, your brand vault, and your competitors already. You are not building integrations. You are composing operations.
This Is Not Just About Perplexity
Everything in this article applies to Perplexity specifically. But the same methodology works across every AI engine, with adjustments for each engine’s biases.
Our data shows that ChatGPT, Claude, and Perplexity don’t agree on anything. The same brand can be rated up to 79 sentiment points apart depending on which engine you ask. Claude heavily favors blog content. ChatGPT favors product pages. Perplexity provides the most citations per mention but never uses Wikipedia.
That means you need engine-specific visibility data to make engine-specific decisions. And you need a system that tracks all of them simultaneously so you are not optimizing for one engine while losing ground on another.
That is exactly what Analyze AI does. Not as a passive dashboard. As an agentic platform for SEO, AEO, content, and GTM ops that can pull data from any source, run any workflow, and push results to any destination. AI search visibility is one of the things it does. It is not the only thing.
If your content is not being cited by answer engines today, the traffic you are missing will only grow. Perplexity surpassed 230 million monthly active users in Q1 2026. Perplexity-referred traffic converts at 3.1x the rate of standard Google organic. The audience is there. The question is whether your brand is showing up when they ask.
Ernest
Ibrahim


![50 GEO Statistics From Tracking 83,670 AI Citations [2026 Data]](/_next/image?url=https%3A%2F%2Fwww.datocms-assets.com%2F164164%2F1779314907-blobid0.png&w=3840&q=75)

