


Summarize this blog post with:
Read almost any blog post about LSI keywords and you’ll be told two things. First, that Google uses a technology called LSI to index web pages. Second, that sprinkling LSI keywords into your content helps you rank higher.
Both claims are technically false.
The interesting part is that the underlying advice (use related words, phrases, and entities in your content) is correct. The labelling is just wrong, and the wrong label leads people to do the wrong things.
In this article, you’ll learn what LSI keywords actually are, why most of what gets written about them is technically wrong, and what to do instead if you want your content to rank in Google and show up in answers from ChatGPT, Perplexity, and Gemini. You’ll also get a step-by-step process for finding the related words, phrases, and entities that genuinely move the needle, using both classic SEO methods and AI search data.
Table of Contents
What are LSI keywords?
LSI keywords are words and phrases that the SEO community considers semantically related to a topic. If you’re writing about cars, LSI keywords might be automobile, engine, tires, transmission, and fuel economy.
That’s the working definition you’ll find in most posts. The problem is that the term “LSI keywords” suggests Google is running a specific 1980s algorithm called Latent Semantic Indexing on the web, which it isn’t. Google’s John Mueller has said this directly:
“There’s no such thing as LSI keywords, anyone who’s telling you otherwise is mistaken, sorry.”
John Mueller, July 30, 2019
So what is LSI, why doesn’t Google use it, and what does Google use? You need to understand the actual technology to make sense of why some of the advice still works and some of it doesn’t.
What is Latent Semantic Indexing (LSI)?
Latent Semantic Indexing (LSI), also called Latent Semantic Analysis (LSA), is a natural language processing technique patented by Bell Communications Research in 1989. It uses linear algebra (specifically, singular value decomposition) to map words and documents into a shared mathematical space, so a computer can spot which terms tend to appear in the same contexts.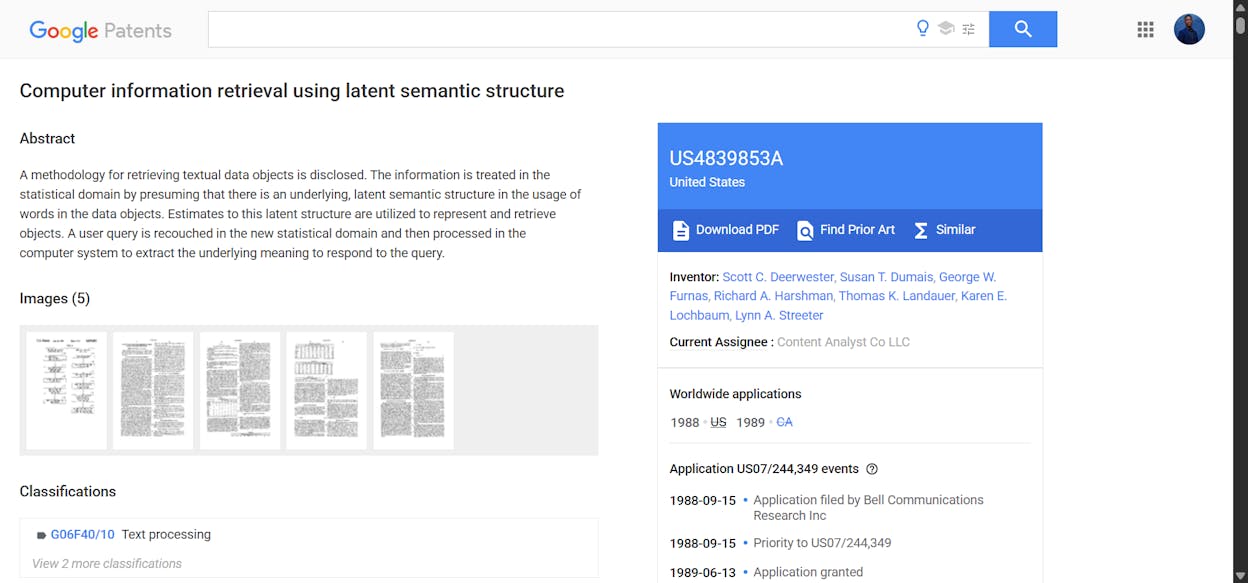
You don’t need the math. You need the problem it was built to solve.
The creators of LSI described it like this:
“The words a searcher uses are often not the same as those by which the information sought has been indexed.”
Two language patterns make this hard for computers. They are synonymy and polysemy.
Synonyms
Synonyms are different words that mean the same thing. Rich and wealthy. Fall and autumn. Cars and automobiles.
Imagine two pages that explain how electric vehicles work, but one uses cars throughout and the other uses automobiles. A search engine that only matched the literal word cars would only return one of them, even though both answer the question. The page that uses automobiles might actually be the more useful one.
To return the best result, a search engine has to recognise that cars and automobiles refer to the same thing.
Polysemy
Polysemic words are single words with multiple meanings. Mouse (the rodent or the input device). Bank (the river bank or the financial institution). Apple (the fruit or the company).
If someone searches for “apple computer,” a system that only matched literal words might return a recipe page that happens to use both terms, even though the user clearly wants Mac products.
LSI was one of the early attempts to teach computers the difference, by analysing how words co-occur across a body of documents and inferring meaning from those patterns.
How does LSI work, in plain English?
Computers don’t know that big and large mean the same thing. Nobody has hand-coded that into them. LSI gives them a way to figure it out from data.
You feed LSI a corpus of documents. It builds a giant matrix that records how often each word appears in each document, then uses singular value decomposition to compress that matrix into a smaller one that captures the strongest patterns of co-occurrence.
The output is a kind of map. Words that appear in similar contexts end up close together. Fall and autumn land near each other. Summer, winter, and spring cluster nearby. The word fall (the season) sits in one neighbourhood, and fall (a stumble or drop) sits in another.
A search engine using LSI can then look up a query, find the region of the map it lives in, and return documents from that same region, even if those documents don’t use the exact query word.
That was clever in the 1980s. It also doesn’t scale to the open web.
Does Google use LSI? No, and here’s why
It’s tempting to assume Google uses LSI, because Google clearly understands synonyms and word meanings. Search “rich” and Google knows you might mean wealthy. Search “mouse” and it knows whether to show you rodents or peripherals based on the rest of the query.
But understanding meaning isn’t the same as using LSI to do it. Google representatives have said many times that they don’t use LSI. There are three structural reasons that confirm it.
LSI was built for small, static document collections. It was designed before the web existed. Bill Slawski, who spent a career reverse-engineering Google’s patents, put it bluntly: using LSI on the modern web “would be like racing a Ferrari with a go-cart.”
LSI requires recomputation every time the corpus changes. The original patent says the analysis has to run “each time there is a significant update in the storage files.” Google indexes hundreds of billions of pages and crawls billions more every day. Recomputing an LSI matrix at that scale, that often, is not realistic.
The LSI patent expired in 2008. Susan Dumais, one of the co-inventors, joined Microsoft in 1997 and helped develop their search technology. Google was already returning relevant results long before the patent expired, using its own approaches.
What Google and AI search engines actually use
This is where most articles about LSI keywords stop. That’s the gap worth filling, because the technology Google actually uses, and the technology powering ChatGPT, Perplexity, and Gemini, is what determines how you should write today.
The modern stack is built on vector embeddings, transformer models, and knowledge graphs.
Vector embeddings are conceptually similar to LSI. Both place words and documents in a mathematical space where similar things sit close together. The difference is that modern embeddings are produced by neural networks trained on enormous text corpora, and they capture far richer relationships than LSI ever could. Word2vec, introduced by Google in 2013, was the first widely-used version. BERT (2018) and MUM (2021) extended the same idea to handle full sentences and context.
|
Technology |
Year |
What it understands |
|---|---|---|
|
Latent Semantic Indexing (LSI) |
1989 |
Word co-occurrence in a fixed corpus |
|
Word2vec |
2013 |
Individual word meanings from web-scale data |
|
RankBrain |
2015 |
Whole-query intent |
|
BERT |
2018 |
Words in the context of the surrounding sentence |
|
MUM |
2021 |
Multimodal context across languages and formats |
|
LLM embeddings (GPT, Gemini, Claude) |
2022+ |
Full passages, documents, and intent at scale |
Knowledge graphs sit alongside the embeddings. Google’s Knowledge Graph stores explicit relationships between people, places, products, and concepts. When you search for “Donald Glover,” Google knows he’s also Childish Gambino, that he was in Atlanta, and that he was born in California, because those relationships are encoded as facts in the graph.
AI search engines use a different but related set of techniques. ChatGPT, Perplexity, Gemini, and Copilot all rely on large language models that encode text into high-dimensional vectors during training. When you ask Perplexity a question, it retrieves passages from the open web, ranks them using semantic similarity to your prompt, and synthesises an answer. The relationships those models learn are far richer than what LSI could ever produce, because they’re built on hundreds of billions of words of training data.
The practical takeaway is that semantic relationships matter more than ever. They just aren’t computed by LSI. If you want to learn how to think about visibility across both worlds, our breakdown of the 4 pillars of an effective SEO strategy for AI search lays out the foundation.
Do related words and entities still help you rank?
Yes. The label “LSI keywords” is wrong, but the underlying behaviour the SEO community recommends (using related words, phrases, and entities) genuinely helps content perform.
Google says so itself, in How Search Works:
“When you search for ‘dogs’, you probably don’t want a page with the word ‘dogs’ on it hundreds of times. Algorithms assess if a page contains other relevant content beyond the keyword ‘dogs’, such as pictures of dogs, videos, or even a list of breeds.”
Two pages can mention the word dogs the same number of times, but if one also talks about Labradors, retrievers, puppy training, and vet visits while the other talks about cats, litter boxes, and scratching posts, Google can tell which one is actually about dogs.
The same dynamic shapes AI search, but the stakes are higher. LLMs don’t just use related terms to figure out what your page is about. They use them to decide whether your page is the best possible answer to a user’s prompt. Every additional relevant entity you mention strengthens the model’s confidence that your page belongs in the answer. This is why entity richness is one of the recurring patterns in how brands win citations from ChatGPT and Perplexity.
So the real question isn’t whether related terms matter. It’s how to find the ones that actually move rankings, in both Google and AI engines, without falling back on guesswork.
How to find and use related words and phrases
Here are nine methods that work, in order from quickest to most thorough. The first five are classic SEO methods. The last four pull from AI search data, which is where the freshest signal lives.
1. Start with what you already know
If you’re writing about a topic you understand, the related terms tend to write themselves. A piece on espresso machines will naturally mention portafilter, grinder, bar pressure, and crema. A piece on backlinks will mention anchor text, referring domains, link velocity, and toxic links.
Before you reach for a tool, draft an outline from memory and list every related term and entity you’d expect a knowledgeable reader to see. This is the cheapest way to get most of the way there.
The catch is that even experts miss things. Our guide to internal linking might forget to mention anchor text optimisation if we wrote it in one sitting. So treat your first draft as a starting point, not a finishing point.
2. Mine Google autocomplete, related searches, and People Also Ask
Type your target keyword into Google. Look at the autocomplete suggestions. Scroll to the bottom and read the related searches. Open a few of the People Also Ask boxes and read what surfaces.
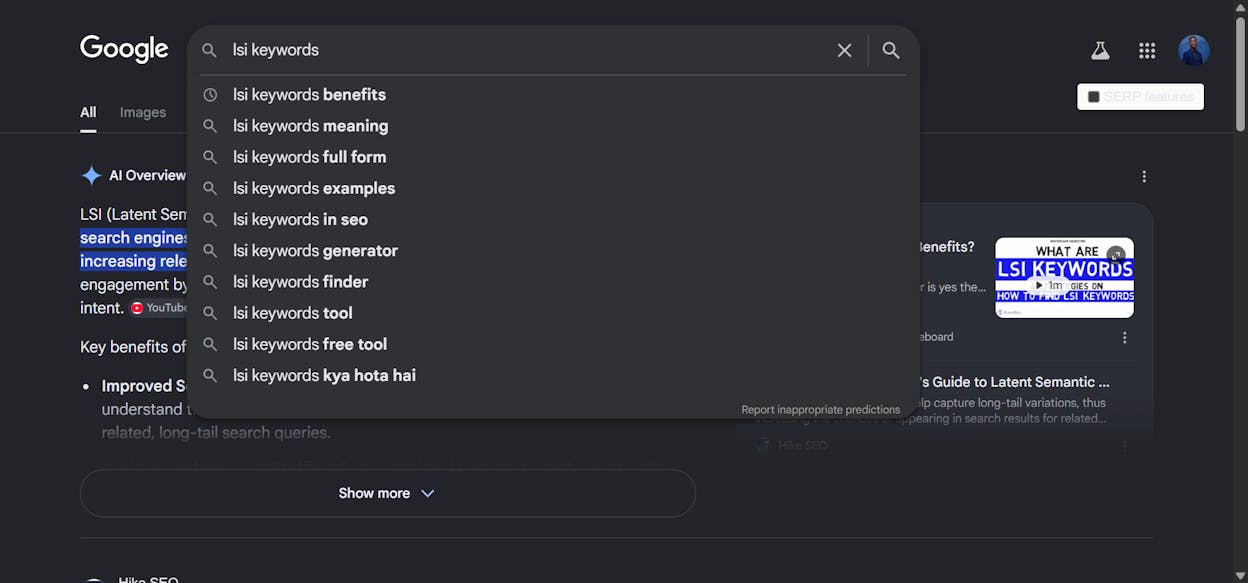
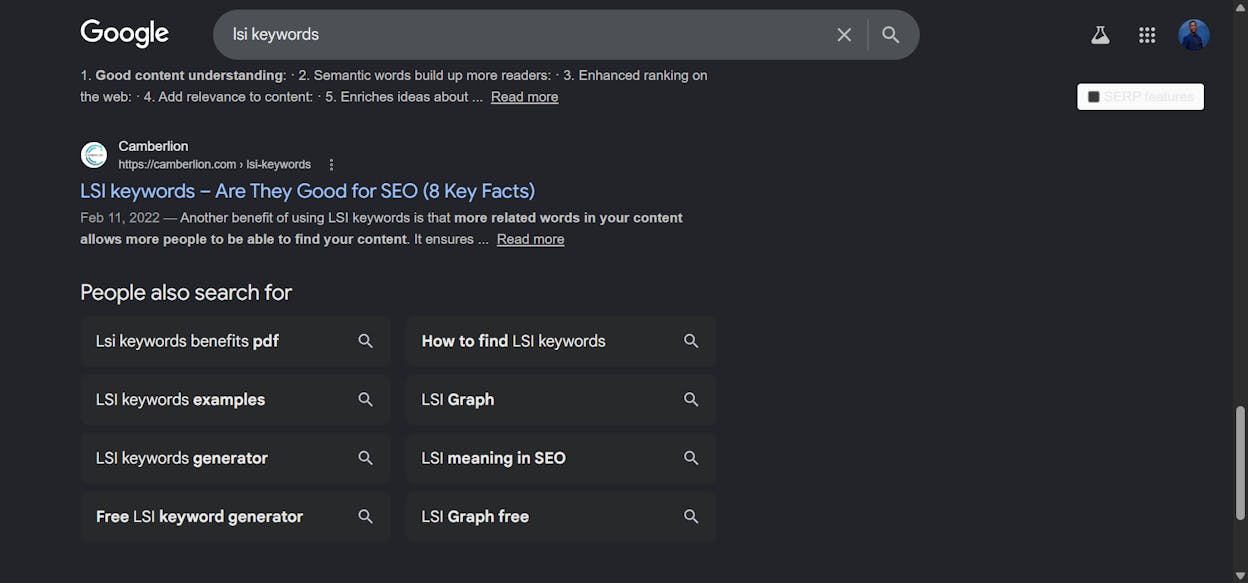
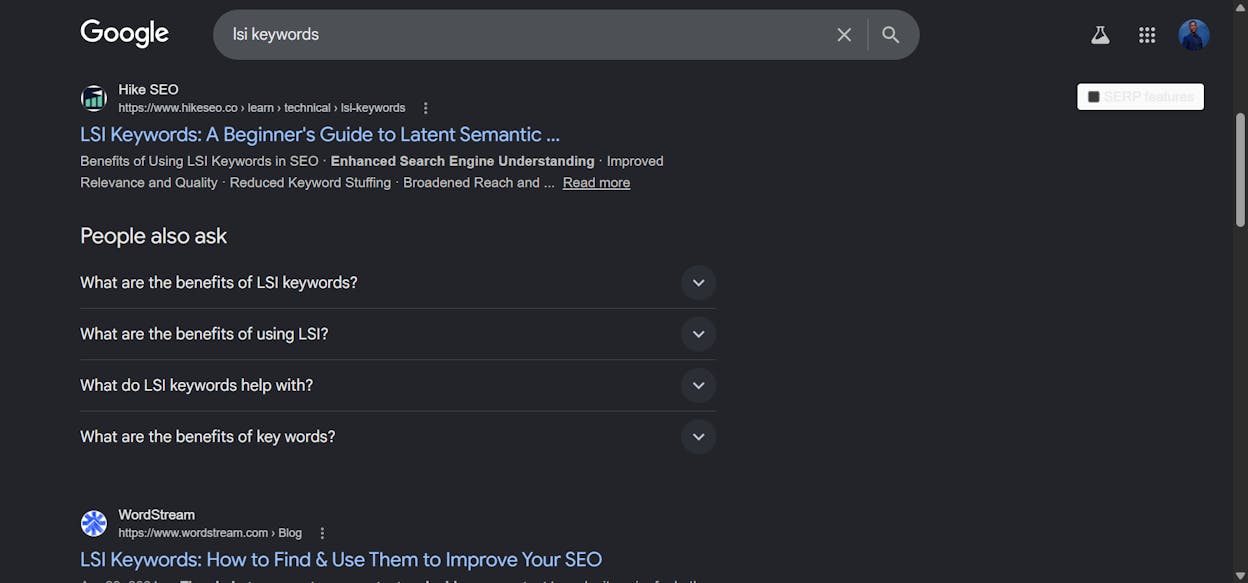
These three places surface entities and angles that real users care about. A search for “donald glover” turns up autocomplete entries for atlanta, childish gambino, and community, all of which a complete article should probably mention. We’ve broken down how to systematically use these signals in our piece on optimising for People Also Ask in AI search.
3. Look at what the top-ranking pages also rank for
The pages already ranking for your target keyword tend to rank for dozens of related terms. Pulling that list gives you a strong shortlist of related queries to address.
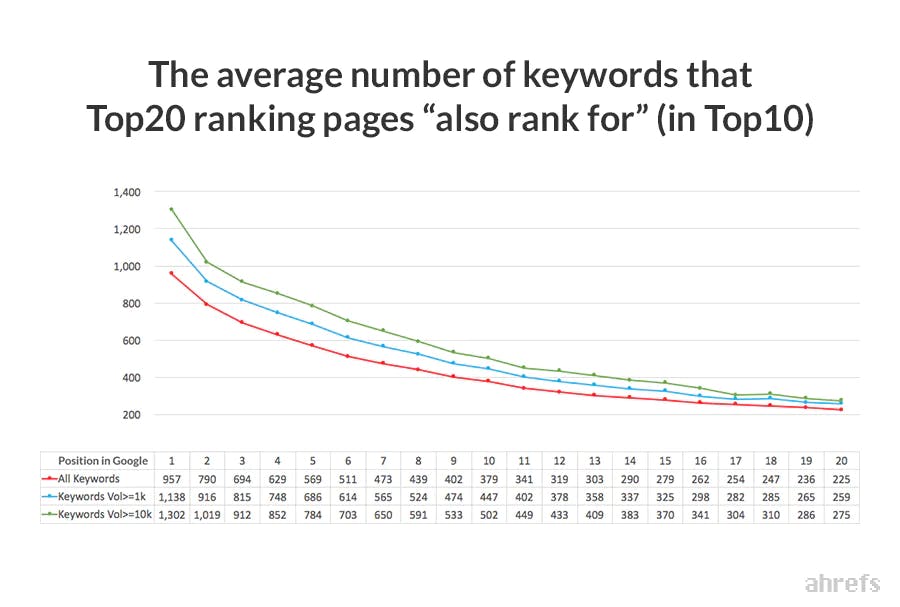
If the list is long, narrow it to the keywords that all of the top-ranking pages share. That intersection is usually the cleanest signal of what Google considers core to the topic. You can speed this up with our free keyword generator tool and SERP checker, then group the results into themes using the process in our keyword clustering guide.
4. Pull entities from Google’s Natural Language API
Paste a top-ranking page into Google’s Natural Language API demo. It returns the entities Google identifies in the text, ranked by how salient they are to the page.
This is the closest you can get to Google’s own view of which entities define a topic. If a competitor’s top-ranking article surfaces ten salient entities and your draft only covers four, you have a clear list of gaps to fill. For more on the entity-first approach, our secondary keywords guide walks through how to integrate them without keyword stuffing.
5. Check the Knowledge Graph and Wikipedia
Knowledge graphs make explicit relationships visible. Search your topic on Google and look for the Knowledge Panel on the right side of the SERP. Open the Wikipedia or Wikidata entry for your topic and skim the “See also” and infobox sections.
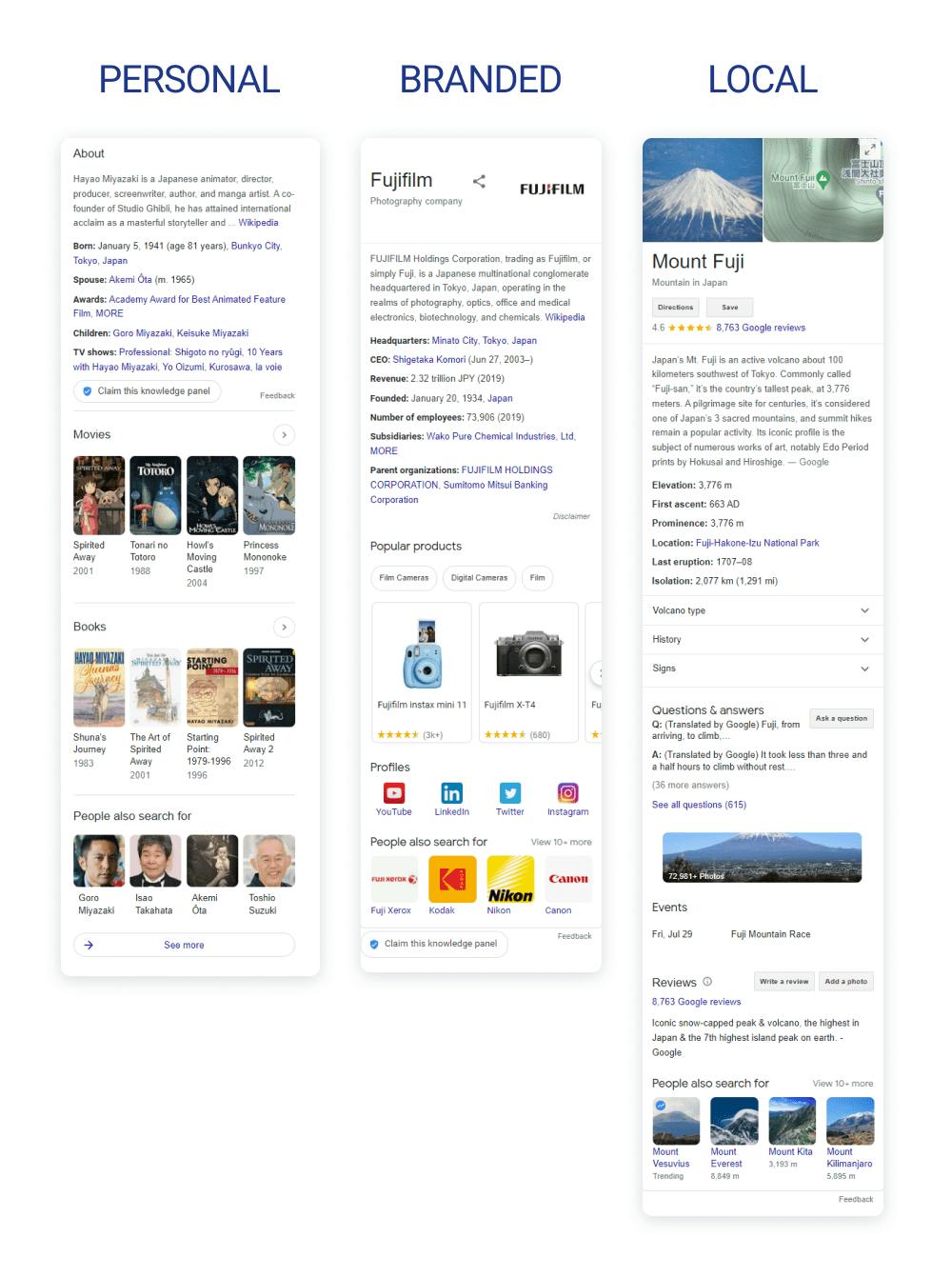
These are the entities Google has formally connected to your topic. Mentioning the relevant ones reinforces Google’s understanding that your page belongs in the conversation.
6. Mine the prompts that AI users actually ask
This is where AI search data starts to outperform classic SEO research. Google autocomplete shows you what people type into a search bar. Prompt data shows you what they actually ask ChatGPT, Perplexity, and Gemini, in full sentences, with intent attached.
In Analyze AI, the Suggested Prompts view returns the prompts most relevant to your space, generated from real AI usage patterns adjacent to the prompts you already track.
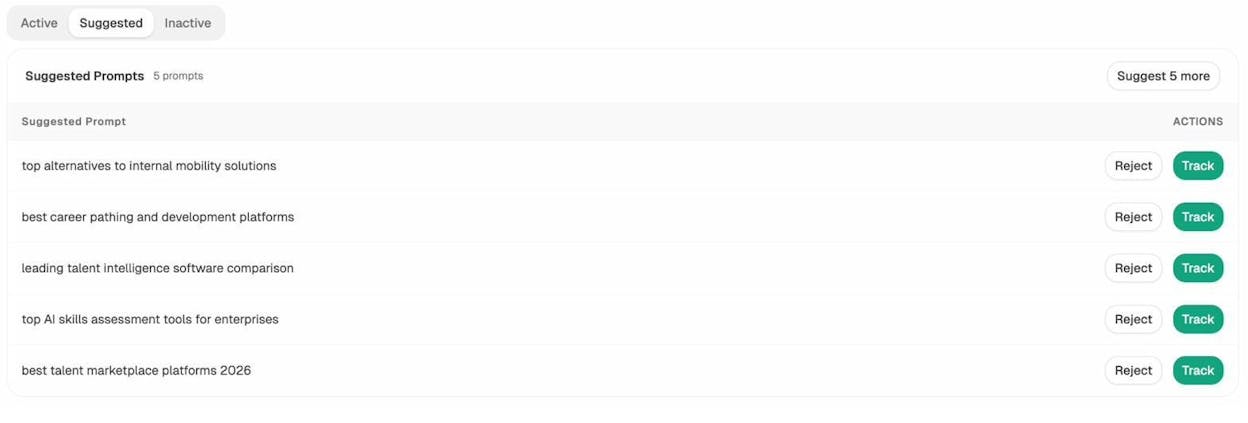
Skim the list. The vocabulary, modifiers, and adjacent entities are exactly the related terms you should weave into your content, because they’re what LLMs already associate with the topic. Our AI keyword research guide goes deeper into this approach. For one-off exploration, our free Bing keyword tool covers the SERP side and Prompt Discovery handles the LLM side.
7. See which language and entities AI engines repeat about your space
This one has no SEO equivalent. Every time an AI engine answers a question about your industry, it repeats certain phrases, entities, and themes. Those repeated patterns are the model’s working vocabulary for your topic.
In Analyze AI, the Perception view surfaces the exact language LLMs reuse when discussing a brand or category, broken down by sentiment.
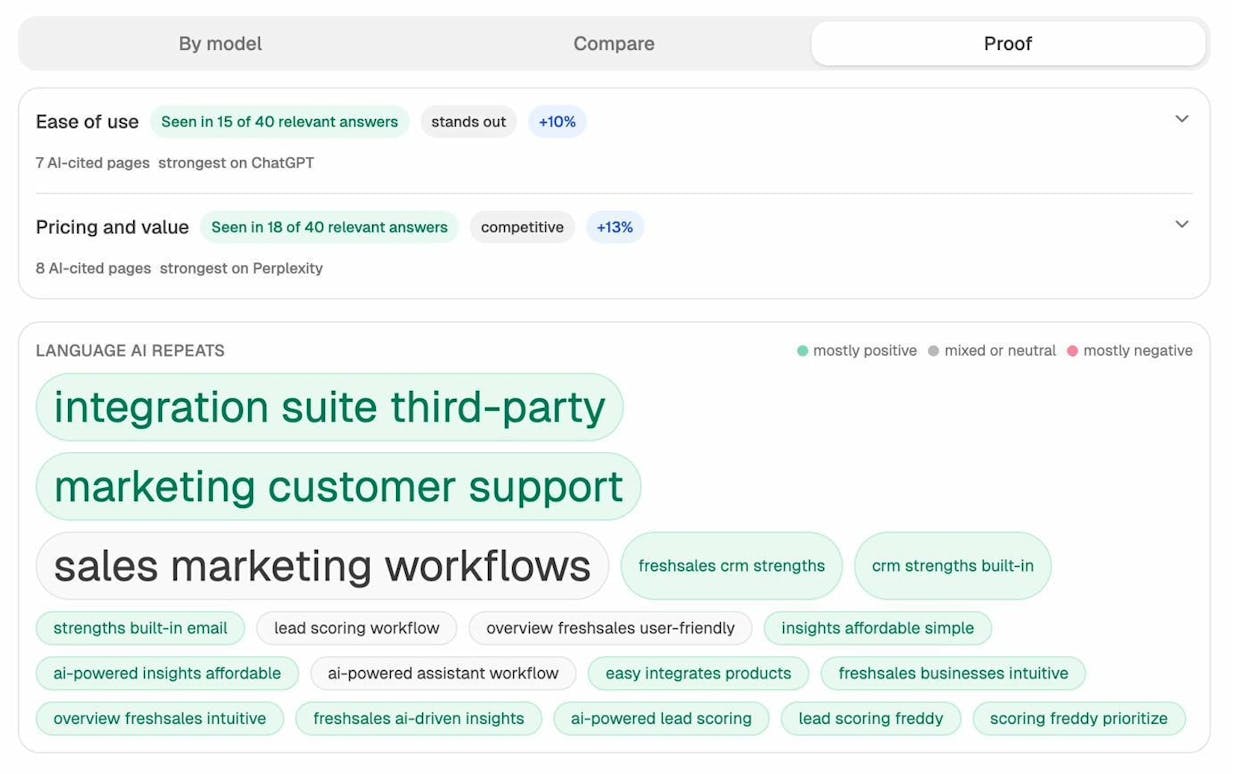
If you’re writing about CRM software and the model keeps repeating integration suite third-party, sales marketing workflows, and lead scoring workflow, those phrases are part of the topic’s actual semantic neighbourhood inside the LLM. Including them, where they fit naturally, makes your content easier for the model to retrieve and cite. The full mechanic is covered in our guide to getting mentioned in AI search.
8. Reverse-engineer the pages AI is already citing
Once you know which pages AI engines cite for your topic, you can study them the way you’d study a top-ranking SERP result. The Sources and Landing Pages views in Analyze AI show you the exact URLs that get cited and the prompts that surface them.
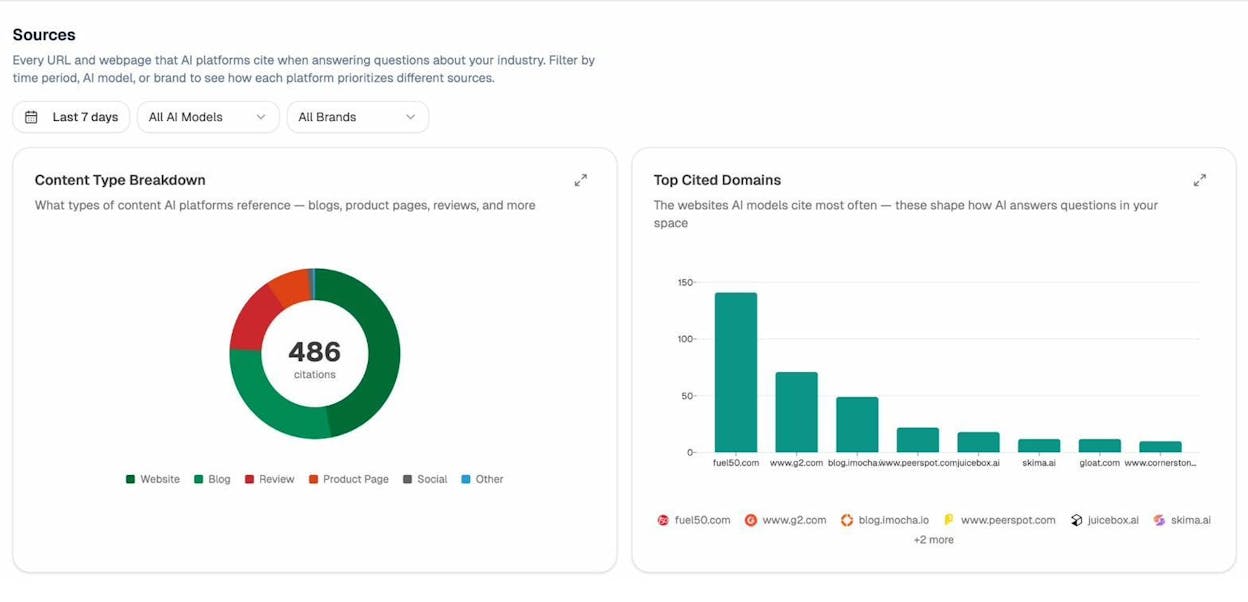
Open the most-cited pages, paste them into Google’s Natural Language API, and pull the entities. You’re now reverse-engineering the entity profile of content that LLMs trust enough to cite. Run that across three or four pages and the shared vocabulary becomes obvious.
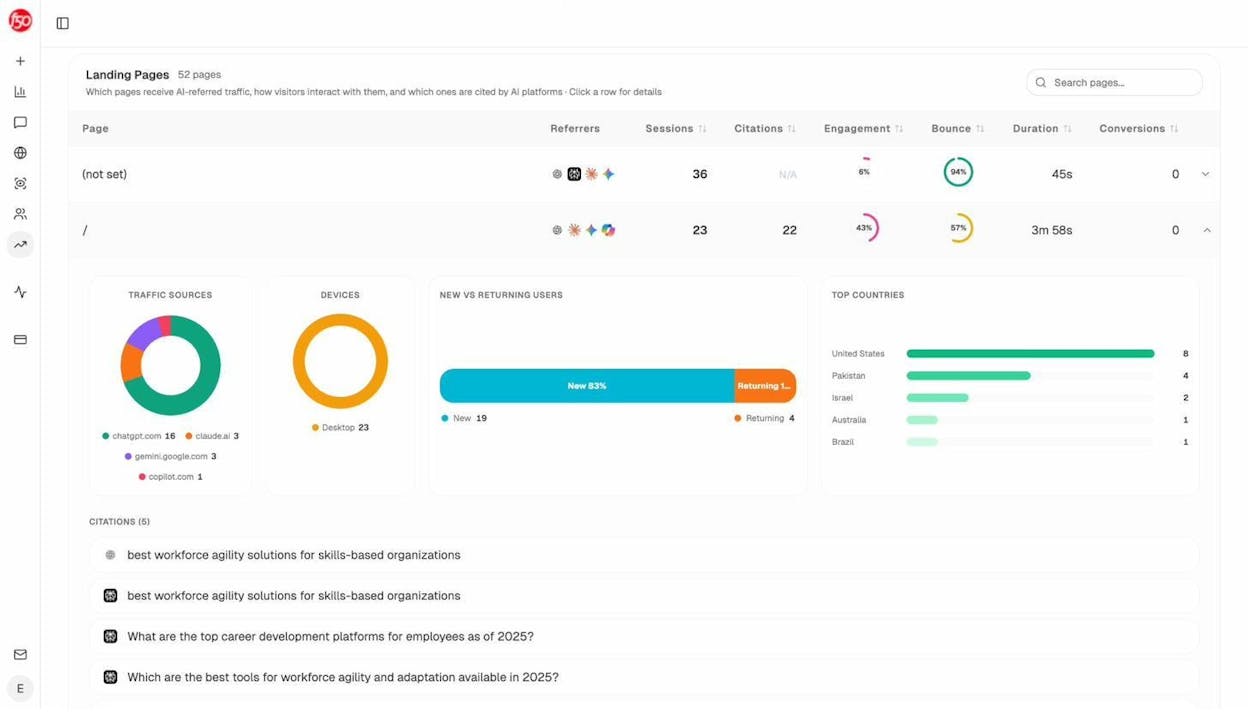
The same data tells you which of your pages already pull AI traffic and on which prompts. Patterns there tell you what’s working in your own content, so you can double down on the structures, entities, and angles AI engines reward.
9. Run the draft through an entity-aware optimiser
Once you have a draft, run it through a tool that compares your entity coverage against what’s already ranking. Analyze AI’s Content Optimizer pulls your existing page, scores it against the top-ranking and most-cited content, and shows the specific entity and topical gaps you should close.
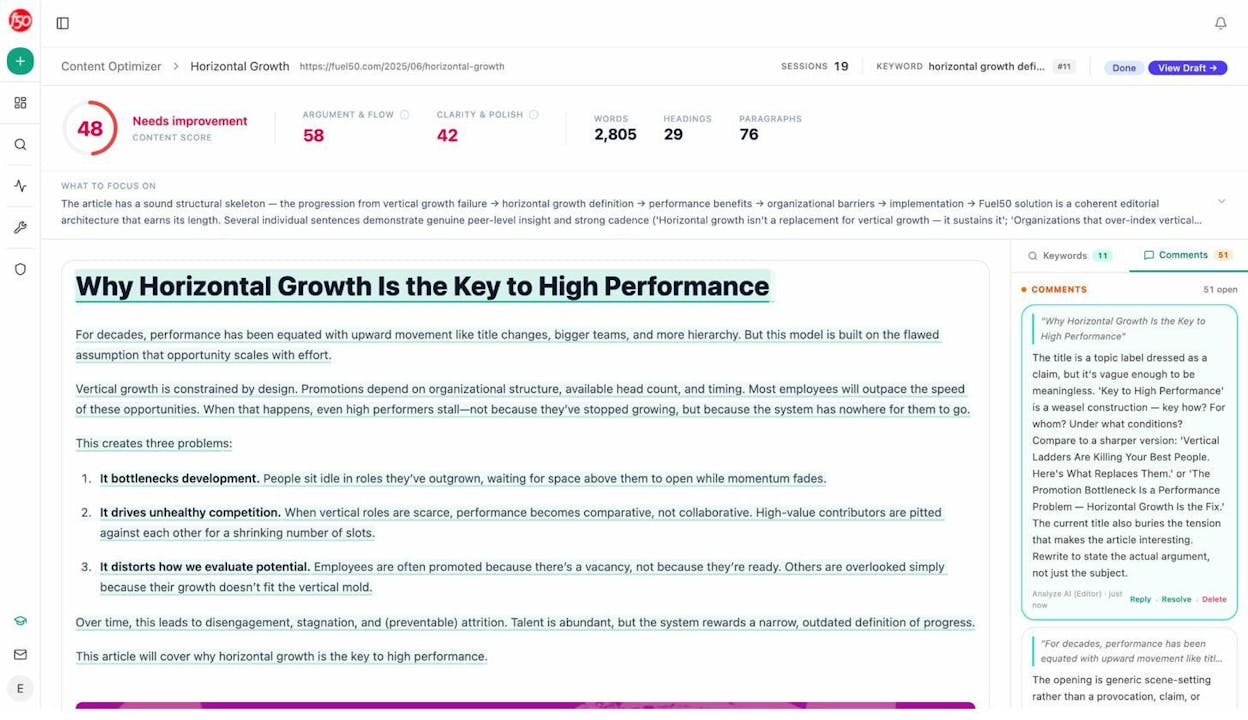
The point isn’t to chase a score. It’s to see at a glance which related terms, entities, and sub-topics your draft is missing, and decide which ones genuinely belong.
How to use related terms without keyword stuffing
Once you have a list of related words, phrases, and entities, the temptation is to sprinkle them into your draft. Don’t. Sprinkling produces awkward sentences that hurt the reader and don’t fool the algorithm.
Use this filter instead:
-
If the term changes what your reader learns, write a section about it. A guide to nofollow links that doesn’t cover sponsored and UGC link attributes is incomplete. The fix is a new section, not a sprinkled phrase.
-
If the term is part of how people naturally talk about the topic, work it into existing prose. Mentioning portafilter in an espresso article doesn’t need its own H2, but it should appear where you describe the machine.
-
If the term is only loosely related, leave it out. A piece on backlink building doesn’t need a paragraph about Donald Trump just because his name appeared in someone’s “related entities” report.
The test is whether the reader is better served by the addition. If yes, keep it. If no, cut it. This is the same logic we apply when updating older posts, and it’s how you build pages that earn rankings in Google and citations in AI engines.
The bottom line
LSI keywords don’t exist as a Google ranking factor, and the 1980s technology they’re named after isn’t what powers modern search. What does power modern search, in both Google and AI engines, is a stack of vector embeddings, transformer models, and knowledge graphs that read your content for meaning, context, and entity coverage.
That changes the game in your favour. You don’t need to memorise an algorithm or sprinkle synonyms. You need to write content that genuinely covers a topic, including the related words, phrases, and entities a reader (or an LLM) would expect to see. The methods above give you a repeatable process for finding those terms, in both classic SEO and AI search, so the related coverage is something your content earns rather than something you bolt on.
That’s the whole job. Cover the topic completely, in the language your readers and the models actually use, and the rankings tend to follow.
Ernest
Ibrahim





